With the abundance of great libraries, in R, for statistical computing, why would you be interested in TensorFlow Probability (TFP, for short)? Well - let’s look at a list of its components:
- Distributions and bijectors (bijectors are reversible, composable maps)
- Probabilistic modeling (Edward2 and probabilistic network layers)
- Probabilistic inference (via MCMC or variational inference)
Now imagine all these working seamlessly with the TensorFlow framework - core, Keras, contributed modules - and also, running distributed and on GPU. The field of possible applications is vast - and far too diverse to cover as a whole in an introductory blog post.
Instead, our aim here is to provide a first introduction to TFP, focusing on direct applicability to and interoperability with deep learning.
We’ll quickly show how to get started with one of the basic building blocks: distributions. Then, we’ll build a variational autoencoder similar to that in Representation learning with MMD-VAE. This time though, we’ll make use of TFP to sample from the prior and approximate posterior distributions.
We’ll regard this post as a “proof on concept” for using TFP with Keras - from R - and plan to follow up with more elaborate examples from the area of semi-supervised representation learning.
Installing and using TFP
To install TFP together with TensorFlow, simply append tensorflow-probability to the default list of extra packages:1
library(tensorflow)
install_tensorflow(
extra_packages = c("keras", "tensorflow-hub", "tensorflow-probability"),
version = "1.12"
)Now to use TFP, all we need to do is import it and create some useful handles.
library(tensorflow)
tfp <- import("tensorflow_probability")
tfd <- tfp$distributionsAnd here we go, sampling from a standard normal distribution.
n <- tfd$Normal(loc = 0, scale = 1)
n$sample(6L)tf.Tensor(
"Normal_1/sample/Reshape:0", shape=(6,), dtype=float32
)Now that’s nice, but it’s 2019, we don’t want to have to create a session to evaluate these tensors anymore. In the variational autoencoder example below, we are going to see how TFP and TF eager execution are the perfect match, so why not start using it now.
To use eager execution, we have to execute the following lines in a fresh (R) session:
library(keras)
use_implementation("tensorflow")
library(tensorflow)
tfe_enable_eager_execution(device_policy = "silent")… and import TFP, same as above.
tfp <- import("tensorflow_probability")
tfd <- tfp$distributionsNow let’s quickly look at TFP distributions.
Using distributions
Here’s that standard normal again.
n <- tfd$Normal(loc = 0, scale = 1)Things commonly done with a distribution include sampling:
# just as in low-level tensorflow, we need to append L to indicate integer arguments
n$sample(6L) tf.Tensor(
[-0.34403768 -0.14122334 -1.3832929 1.618252 1.364448 -1.1299014 ],
shape=(6,),
dtype=float32
)As well as getting the log probability. Here we do that simultaneously for three values.
n$log_prob(c(-1, 0, 1))tf.Tensor(
[-1.4189385 -0.9189385 -1.4189385], shape=(3,), dtype=float32
)We can do the same things with lots of other distributions, e.g., the Bernoulli:
b <- tfd$Bernoulli(0.9)
b$sample(10L)tf.Tensor(
[1 1 1 0 1 1 0 1 0 1], shape=(10,), dtype=int32
)b$log_prob(c(0,1,0,0))tf.Tensor(
[-1.2411538 -0.3411539 -1.2411538 -1.2411538], shape=(4,), dtype=float32
)Note that in the last chunk, we are asking for the log probabilities of four independent draws.
Batch shapes and event shapes
In TFP, we can do the following.
tfp.distributions.Normal(
"Normal/", batch_shape=(3,), event_shape=(), dtype=float32
)Contrary to what it might look like, this is not a multivariate normal. As indicated by batch_shape=(3,), this is a “batch” of independent univariate distributions. The fact that these are univariate is seen in event_shape=(): Each of them lives in one-dimensional event space.
If instead we create a single, two-dimensional multivariate normal:
tfp.distributions.MultivariateNormalDiag(
"MultivariateNormalDiag/", batch_shape=(), event_shape=(2,), dtype=float32
)we see batch_shape=(), event_shape=(2,), as expected.
Of course, we can combine both, creating batches of multivariate distributions:
This example defines a batch of three two-dimensional multivariate normal distributions.
Converting between batch shapes and event shapes
Strange as it may sound, situations arise where we want to transform distribution shapes between these types - in fact, we’ll see such a case very soon.
tfd$Independent is used to convert dimensions in batch_shape to dimensions in event_shape.
Here is a batch of three independent Bernoulli distributions.
bs <- tfd$Bernoulli(probs=c(.3,.5,.7))
bstfp.distributions.Bernoulli(
"Bernoulli/", batch_shape=(3,), event_shape=(), dtype=int32
)We can convert this to a virtual “three-dimensional” Bernoulli like this:
b <- tfd$Independent(bs, reinterpreted_batch_ndims = 1L)
btfp.distributions.Independent(
"IndependentBernoulli/", batch_shape=(), event_shape=(3,), dtype=int32
)Here reinterpreted_batch_ndims tells TFP how many of the batch dimensions are being used for the event space, starting to count from the right of the shape list.
With this basic understanding of TFP distributions, we’re ready to see them used in a VAE.
Variational autoencoder using TFP
We’ll take the (not so) deep convolutional architecture from Representation learning with MMD-VAE and use distributions for sampling and computing probabilities. Optionally, our new VAE will be able to learn the prior distribution.
Concretely, the following exposition will consist of three parts. First, we present common code applicable to both a VAE with a static prior, and one that learns the parameters of the prior distribution. Then, we have the training loop for the first (static-prior) VAE. Finally, we discuss the training loop and additional model involved in the second (prior-learning) VAE.
Presenting both versions one after the other leads to code duplications, but avoids scattering confusing if-else branches throughout the code.
The second VAE is available as part of the Keras examples so you don’t have to copy out code snippets. The code also contains additional functionality not discussed and replicated here, such as for saving model weights.
So, let’s start with the common part.
At the risk of repeating ourselves, here again are the preparatory steps (including a few additional library loads).
library(keras)
use_implementation("tensorflow")
library(tensorflow)
tfe_enable_eager_execution(device_policy = "silent")
tfp <- import("tensorflow_probability")
tfd <- tfp$distributions
library(tfdatasets)
library(dplyr)
library(glue)Dataset
For a change from MNIST and Fashion-MNIST, we’ll use the brand new Kuzushiji-MNIST(Clanuwat et al. 2018).

As in that other post, we stream the data via tfdatasets:
buffer_size <- 60000
batch_size <- 256
batches_per_epoch <- buffer_size / batch_size
train_dataset <- tensor_slices_dataset(train_images) %>%
dataset_shuffle(buffer_size) %>%
dataset_batch(batch_size)Now let’s see what changes in the encoder and decoder models.
Encoder
The encoder differs from what we had without TFP in that it does not return the approximate posterior means and variances directly as tensors. Instead, it returns a batch of multivariate normal distributions:
# you might want to change this depending on the dataset
latent_dim <- 2
encoder_model <- function(name = NULL) {
keras_model_custom(name = name, function(self) {
self$conv1 <-
layer_conv_2d(
filters = 32,
kernel_size = 3,
strides = 2,
activation = "relu"
)
self$conv2 <-
layer_conv_2d(
filters = 64,
kernel_size = 3,
strides = 2,
activation = "relu"
)
self$flatten <- layer_flatten()
self$dense <- layer_dense(units = 2 * latent_dim)
function (x, mask = NULL) {
x <- x %>%
self$conv1() %>%
self$conv2() %>%
self$flatten() %>%
self$dense()
tfd$MultivariateNormalDiag(
loc = x[, 1:latent_dim],
scale_diag = tf$nn$softplus(x[, (latent_dim + 1):(2 * latent_dim)] + 1e-5)
)
}
})
}Let’s try this out.
encoder <- encoder_model()
iter <- make_iterator_one_shot(train_dataset)
x <- iterator_get_next(iter)
approx_posterior <- encoder(x)
approx_posteriortfp.distributions.MultivariateNormalDiag(
"MultivariateNormalDiag/", batch_shape=(256,), event_shape=(2,), dtype=float32
)approx_posterior$sample()tf.Tensor(
[[ 5.77791929e-01 -1.64988488e-02]
[ 7.93901443e-01 -1.00042784e+00]
[-1.56279251e-01 -4.06365871e-01]
...
...
[-6.47531569e-01 2.10889503e-02]], shape=(256, 2), dtype=float32)
We don’t know about you, but we still enjoy the ease of inspecting values with eager execution - a lot.
Now, on to the decoder, which too returns a distribution instead of a tensor.
Decoder
In the decoder, we see why transformations between batch shape and event shape are useful.
The output of self$deconv3 is four-dimensional. What we need is an on-off-probability for every pixel.
Formerly, this was accomplished by feeding the tensor into a dense layer and applying a sigmoid activation.
Here, we use tfd$Independent to effectively tranform the tensor into a probability distribution over three-dimensional images (width, height, channel(s)).
decoder_model <- function(name = NULL) {
keras_model_custom(name = name, function(self) {
self$dense <- layer_dense(units = 7 * 7 * 32, activation = "relu")
self$reshape <- layer_reshape(target_shape = c(7, 7, 32))
self$deconv1 <-
layer_conv_2d_transpose(
filters = 64,
kernel_size = 3,
strides = 2,
padding = "same",
activation = "relu"
)
self$deconv2 <-
layer_conv_2d_transpose(
filters = 32,
kernel_size = 3,
strides = 2,
padding = "same",
activation = "relu"
)
self$deconv3 <-
layer_conv_2d_transpose(
filters = 1,
kernel_size = 3,
strides = 1,
padding = "same"
)
function (x, mask = NULL) {
x <- x %>%
self$dense() %>%
self$reshape() %>%
self$deconv1() %>%
self$deconv2() %>%
self$deconv3()
tfd$Independent(tfd$Bernoulli(logits = x),
reinterpreted_batch_ndims = 3L)
}
})
}Let’s try this out too.
decoder <- decoder_model()
decoder_likelihood <- decoder(approx_posterior_sample)tfp.distributions.Independent(
"IndependentBernoulli/", batch_shape=(256,), event_shape=(28, 28, 1), dtype=int32
)This distribution will be used to generate the “reconstructions,” as well as determine the loglikelihood of the original samples.
KL loss and optimizer
Both VAEs discussed below will need an optimizer …
optimizer <- tf$train$AdamOptimizer(1e-4)… and both will delegate to compute_kl_loss to compute the KL part of the loss.
This helper function simply subtracts the log likelihood of the samples2 under the prior from their loglikelihood under the approximate posterior.
compute_kl_loss <- function(
latent_prior,
approx_posterior,
approx_posterior_sample) {
kl_div <- approx_posterior$log_prob(approx_posterior_sample) -
latent_prior$log_prob(approx_posterior_sample)
avg_kl_div <- tf$reduce_mean(kl_div)
avg_kl_div
}Now that we’ve looked at the common parts, we first discuss how to train a VAE with a static prior.
VAE with static prior
In this VAE, we use TFP to create the usual isotropic Gaussian prior. We then directly sample from this distribution in the training loop.
latent_prior <- tfd$MultivariateNormalDiag(
loc = tf$zeros(list(latent_dim)),
scale_identity_multiplier = 1
)And here is the complete training loop. We’ll point out the crucial TFP-related steps below.
for (epoch in seq_len(num_epochs)) {
iter <- make_iterator_one_shot(train_dataset)
total_loss <- 0
total_loss_nll <- 0
total_loss_kl <- 0
until_out_of_range({
x <- iterator_get_next(iter)
with(tf$GradientTape(persistent = TRUE) %as% tape, {
approx_posterior <- encoder(x)
approx_posterior_sample <- approx_posterior$sample()
decoder_likelihood <- decoder(approx_posterior_sample)
nll <- -decoder_likelihood$log_prob(x)
avg_nll <- tf$reduce_mean(nll)
kl_loss <- compute_kl_loss(
latent_prior,
approx_posterior,
approx_posterior_sample
)
loss <- kl_loss + avg_nll
})
total_loss <- total_loss + loss
total_loss_nll <- total_loss_nll + avg_nll
total_loss_kl <- total_loss_kl + kl_loss
encoder_gradients <- tape$gradient(loss, encoder$variables)
decoder_gradients <- tape$gradient(loss, decoder$variables)
optimizer$apply_gradients(purrr::transpose(list(
encoder_gradients, encoder$variables
)),
global_step = tf$train$get_or_create_global_step())
optimizer$apply_gradients(purrr::transpose(list(
decoder_gradients, decoder$variables
)),
global_step = tf$train$get_or_create_global_step())
})
cat(
glue(
"Losses (epoch): {epoch}:",
" {(as.numeric(total_loss_nll)/batches_per_epoch) %>% round(4)} nll",
" {(as.numeric(total_loss_kl)/batches_per_epoch) %>% round(4)} kl",
" {(as.numeric(total_loss)/batches_per_epoch) %>% round(4)} total"
),
"\n"
)
}Above, playing around with the encoder and the decoder, we’ve already seen how
approx_posterior <- encoder(x)gives us a distribution we can sample from. We use it to obtain samples from the approximate posterior:
approx_posterior_sample <- approx_posterior$sample()These samples, we take them and feed them to the decoder, who gives us on-off-likelihoods for image pixels.
decoder_likelihood <- decoder(approx_posterior_sample)Now the loss consists of the usual ELBO components: reconstruction loss and KL divergence. The reconstruction loss we directly obtain from TFP, using the learned decoder distribution to assess the likelihood of the original input.
nll <- -decoder_likelihood$log_prob(x)
avg_nll <- tf$reduce_mean(nll)The KL loss we get from compute_kl_loss, the helper function we saw above:
kl_loss <- compute_kl_loss(
latent_prior,
approx_posterior,
approx_posterior_sample
)We add both and arrive at the overall VAE loss:
loss <- kl_loss + avg_nllApart from these changes due to using TFP, the training process is just normal backprop, the way it looks using eager execution.
VAE with learnable prior (mixture of Gaussians)
Now let’s see how instead of using the standard isotropic Gaussian, we could learn a mixture of Gaussians.
The choice of number of distributions here is pretty arbitrary. Just as with latent_dim, you might want to experiment and find out what works best on your dataset.
mixture_components <- 16
learnable_prior_model <- function(name = NULL, latent_dim, mixture_components) {
keras_model_custom(name = name, function(self) {
self$loc <-
tf$get_variable(
name = "loc",
shape = list(mixture_components, latent_dim),
dtype = tf$float32
)
self$raw_scale_diag <- tf$get_variable(
name = "raw_scale_diag",
shape = c(mixture_components, latent_dim),
dtype = tf$float32
)
self$mixture_logits <-
tf$get_variable(
name = "mixture_logits",
shape = c(mixture_components),
dtype = tf$float32
)
function (x, mask = NULL) {
tfd$MixtureSameFamily(
components_distribution = tfd$MultivariateNormalDiag(
loc = self$loc,
scale_diag = tf$nn$softplus(self$raw_scale_diag)
),
mixture_distribution = tfd$Categorical(logits = self$mixture_logits)
)
}
})
}In TFP terminology, components_distribution is the underlying distribution type, and mixture_distribution holds the probabilities that individual components are chosen.
Note how self$loc, self$raw_scale_diag and self$mixture_logits are TensorFlow Variables and thus, persistent and updatable by backprop.
Now we create the model.
latent_prior_model <- learnable_prior_model(
latent_dim = latent_dim,
mixture_components = mixture_components
)How do we obtain a latent prior distribution we can sample from? A bit unusually, this model will be called without an input:
latent_prior <- latent_prior_model(NULL)
latent_priortfp.distributions.MixtureSameFamily(
"MixtureSameFamily/", batch_shape=(), event_shape=(2,), dtype=float32
)Here now is the complete training loop. Note how we have a third model to backprop through.
for (epoch in seq_len(num_epochs)) {
iter <- make_iterator_one_shot(train_dataset)
total_loss <- 0
total_loss_nll <- 0
total_loss_kl <- 0
until_out_of_range({
x <- iterator_get_next(iter)
with(tf$GradientTape(persistent = TRUE) %as% tape, {
approx_posterior <- encoder(x)
approx_posterior_sample <- approx_posterior$sample()
decoder_likelihood <- decoder(approx_posterior_sample)
nll <- -decoder_likelihood$log_prob(x)
avg_nll <- tf$reduce_mean(nll)
latent_prior <- latent_prior_model(NULL)
kl_loss <- compute_kl_loss(
latent_prior,
approx_posterior,
approx_posterior_sample
)
loss <- kl_loss + avg_nll
})
total_loss <- total_loss + loss
total_loss_nll <- total_loss_nll + avg_nll
total_loss_kl <- total_loss_kl + kl_loss
encoder_gradients <- tape$gradient(loss, encoder$variables)
decoder_gradients <- tape$gradient(loss, decoder$variables)
prior_gradients <-
tape$gradient(loss, latent_prior_model$variables)
optimizer$apply_gradients(purrr::transpose(list(
encoder_gradients, encoder$variables
)),
global_step = tf$train$get_or_create_global_step())
optimizer$apply_gradients(purrr::transpose(list(
decoder_gradients, decoder$variables
)),
global_step = tf$train$get_or_create_global_step())
optimizer$apply_gradients(purrr::transpose(list(
prior_gradients, latent_prior_model$variables
)),
global_step = tf$train$get_or_create_global_step())
})
checkpoint$save(file_prefix = checkpoint_prefix)
cat(
glue(
"Losses (epoch): {epoch}:",
" {(as.numeric(total_loss_nll)/batches_per_epoch) %>% round(4)} nll",
" {(as.numeric(total_loss_kl)/batches_per_epoch) %>% round(4)} kl",
" {(as.numeric(total_loss)/batches_per_epoch) %>% round(4)} total"
),
"\n"
)
} And that’s it! For us, both VAEs yielded similar results, and we did not experience great differences from experimenting with latent dimensionality and the number of mixture distributions. But again, we wouldn’t want to generalize to other datasets, architectures, etc.
Speaking of results, how do they look? Here we see letters generated after 40 epochs of training. On the left are random letters, on the right, the usual VAE grid display of latent space.
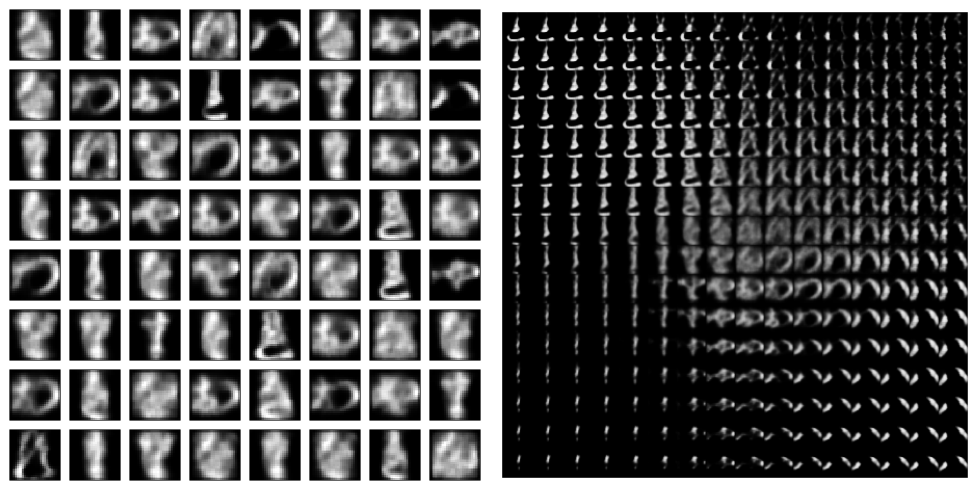
Wrapping up
Hopefully, we’ve succeeded in showing that TensorFlow Probability, eager execution, and Keras make for an attractive combination! If you relate total amount of code required to the complexity of the task, as well as depth of the concepts involved, this should appear as a pretty concise implementation.
In the nearer future, we plan to follow up with more involved applications of TensorFlow Probability, mostly from the area of representation learning. Stay tuned!
At the time we’re publishing this post, we need to pass the “version” argument to enforce compatibility between TF and TFP. This is due to a quirk in TF’s handling of embedded Python that has us temporarily install TF 1.10 by default, until that quirk is to disappear with the upcoming release of TF 1.13.↩︎
Just to be clear: by samples here we mean “samples from the approximate posterior”↩︎