Highlights
sparklyr and friends have been getting some important updates in the past few
months, here are some highlights:
spark_apply()now works on Databricks Connect v2sparkxgbis coming back to lifeSupport for Spark 2.3 and below has ended
pysparklyr 0.1.4
spark_apply() now works on Databricks Connect v2. The latest pysparklyr
release uses the rpy2 Python library as the backbone of the integration.
Databricks Connect v2, is based on Spark Connect. At this time, it supports
Python user-defined functions (UDFs), but not R user-defined functions.
Using rpy2 circumvents this limitation. As shown in the diagram, sparklyr
sends the the R code to the locally installed rpy2, which in turn sends it
to Spark. Then the rpy2 installed in the remote Databricks cluster will run
the R code.
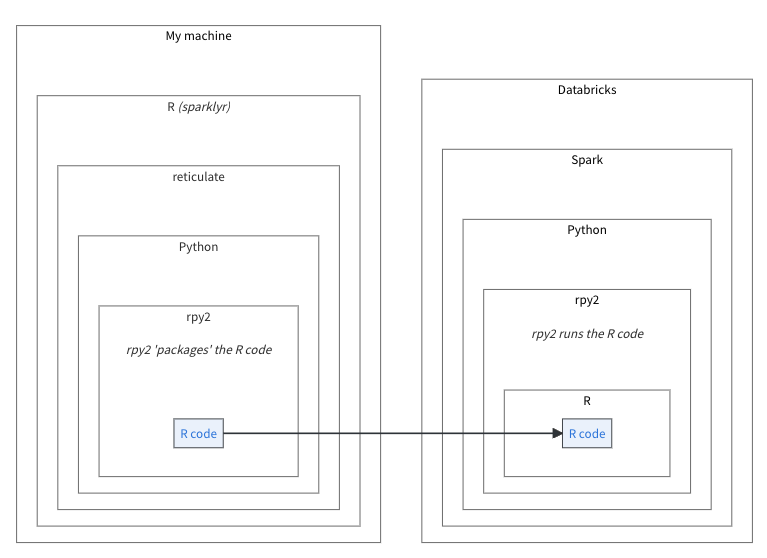
Figure 1: R code via rpy2
A big advantage of this approach, is that rpy2 supports Arrow. In fact it
is the recommended Python library to use when integrating Spark, Arrow and
R.
This means that the data exchange between the three environments will be much
faster!
As in its original implementation, schema inferring works, and as with the original implementation, it has a performance cost. But unlike the original, this implementation will return a ‘columns’ specification that you can use for the next time you run the call.
spark_apply(
tbl_mtcars,
nrow,
group_by = "am"
)
#> To increase performance, use the following schema:
#> columns = "am double, x long"
#> # Source: table<`sparklyr_tmp_table_b84460ea_b1d3_471b_9cef_b13f339819b6`> [2 x 2]
#> # Database: spark_connection
#> am x
#> <dbl> <dbl>
#> 1 0 19
#> 2 1 13A full article about this new capability is available here: Run R inside Databricks Connect
sparkxgb
The sparkxgb is an extension of sparklyr. It enables integration with
XGBoost. The current CRAN release
does not support the latest versions of XGBoost. This limitation has recently
prompted a full refresh of sparkxgb. Here is a summary of the improvements,
which are currently in the development version of the package:
The
xgboost_classifier()andxgboost_regressor()functions no longer pass values of two arguments. These were deprecated by XGBoost and cause an error if used. In the R function, the arguments will remain for backwards compatibility, but will generate an informative error if not leftNULL:sketch_eps- As of XGBoost version 1.6.0sketch_epswas replaced bymax_binstimeout_request_workers- Removed in XGBoost version 1.7.0 because it was no longer needed when XGBoost added barrier support
Updates the JVM version used during the Spark session. It now uses xgboost4j-spark version 2.0.3, instead of 0.8.1. This gives us access to XGboost’s most recent Spark code.
Updates code that used deprecated functions from upstream R dependencies. It also stops using an un-maintained package as a dependency (
forge). This eliminated all of the warnings that were happening when fitting a model.Major improvements to package testing. Unit tests were updated and expanded, the way
sparkxgbautomatically starts and stops the Spark session for testing was modernized, and the continuous integration tests were restored. This will ensure the package’s health going forward.
remotes::install_github("rstudio/sparkxgb")
library(sparkxgb)
library(sparklyr)
sc <- spark_connect(master = "local")
iris_tbl <- copy_to(sc, iris)
xgb_model <- xgboost_classifier(
iris_tbl,
Species ~ .,
num_class = 3,
num_round = 50,
max_depth = 4
)
xgb_model %>%
ml_predict(iris_tbl) %>%
select(Species, predicted_label, starts_with("probability_")) %>%
dplyr::glimpse()
#> Rows: ??
#> Columns: 5
#> Database: spark_connection
#> $ Species <chr> "setosa", "setosa", "setosa", "setosa", "setosa…
#> $ predicted_label <chr> "setosa", "setosa", "setosa", "setosa", "setosa…
#> $ probability_setosa <dbl> 0.9971547, 0.9948581, 0.9968392, 0.9968392, 0.9…
#> $ probability_versicolor <dbl> 0.002097376, 0.003301427, 0.002284616, 0.002284…
#> $ probability_virginica <dbl> 0.0007479066, 0.0018403779, 0.0008762418, 0.000…sparklyr 1.8.5
The new version of sparklyr does not have user facing improvements. But
internally, it has crossed an important milestone. Support for Spark version 2.3
and below has effectively ended. The Scala
code needed to do so is no longer part of the package. As per Spark’s versioning
policy, found here,
Spark 2.3 was ‘end-of-life’ in 2018.
This is part of a larger, and ongoing effort to make the immense code-base of
sparklyr a little easier to maintain, and hence reduce the risk of failures.
As part of the same effort, the number of upstream packages that sparklyr
depends on have been reduced. This has been happening across multiple CRAN
releases, and in this latest release tibble, and rappdirs are no longer
imported by sparklyr.